Low-Latency Detection
I work on real-time gravitational-wave detection, alert generation, and follow-up readiness, with an emphasis on operational reliability inside the LVK collaboration.
I focus on the parts of the pipeline that have to work under time pressure: trigger reliability, handoff between analysis stages, and the coordination needed to make alerts useful to observers. This is the operational side of gravitational-wave astronomy, and it is what makes sky localization and follow-up scientifically actionable.
The broader low-latency problem is not only speed. Alerts have to be reliable enough to trust, informative enough to use, and reproducible enough to interpret later. In practice that means end-to-end testing, validation against injections or replayed data, and careful accounting of what information is available at each stage of the pipeline.
What I Focus On
End-to-end alert products
Low-latency analysis is only useful if the end product can guide follow-up. I care about the chain from data ingestion to triggers, annotations, localization products, and public alerts.
Operational validation
Performance studies need realistic replays and injections. The relevant question is how the system behaves in observing-run conditions, not just whether a pipeline works on paper.
Follow-up readiness
Alerts matter because they support electromagnetic and neutrino follow-up. That means the localization and source-summary products have to be available quickly and in a form that other observers can use.
Representative Papers
- Low-latency gravitational wave alert products and their performance at the time of the fourth LIGO-Virgo-KAGRA observing run
- Low-Latency Gravitational Wave Alerts for Multi-Messenger Astronomy During the Second Advanced LIGO and Virgo Observing Run
- Investigating the effect of sensitivity of KAGRA on sky localization of gravitational-wave sources from compact binary coalescences
Low-latency work is not just about making a pipeline fast. The alert has to be trustworthy, the latency has to be measured honestly, and the output has to be useful to observers who are making decisions in real time. That means paying attention to ingestion, candidate generation, annotations, and public alert products.
The relevant question is whether the pipeline behaves well in observing-run conditions. Replayed data and injection campaigns matter because they expose the failure modes that only show up under operational load.
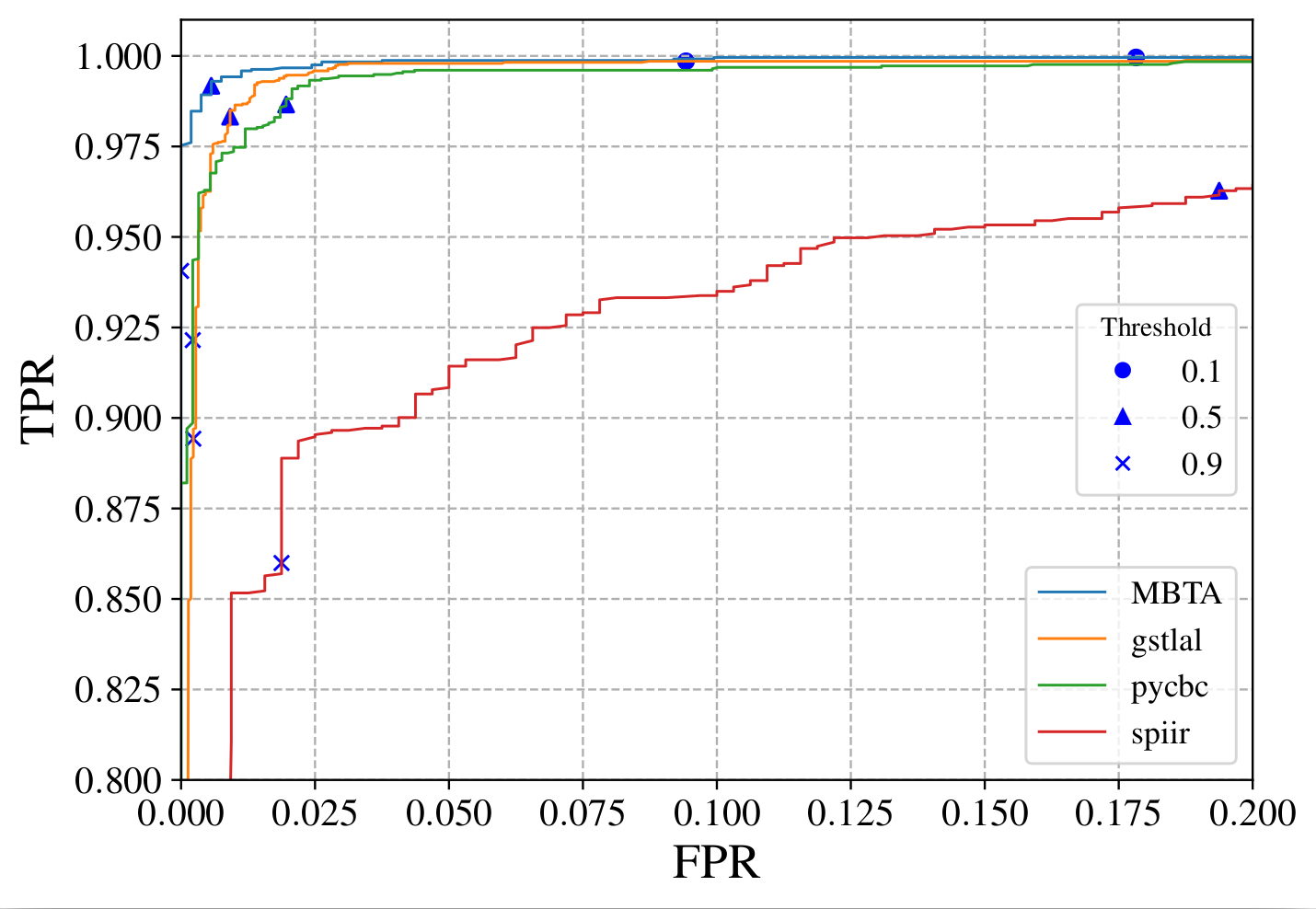
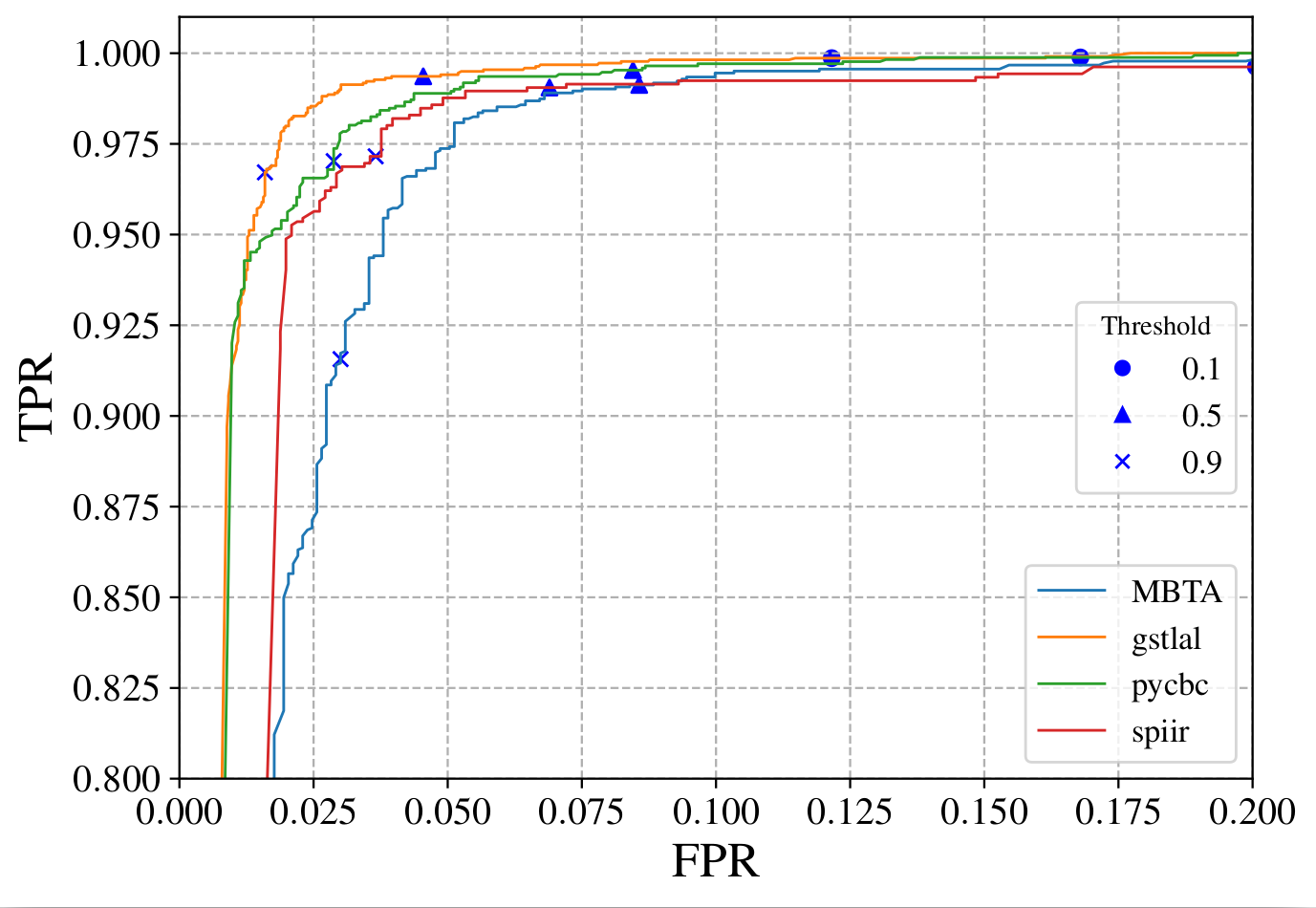

These plots are the right kind of figure for this topic: they show how well the alert products discriminate relevant source classes, which is exactly what matters when an observing team is deciding whether and how to follow up a trigger.